Indiestep Localization Tutorial
とりあえずは最近の Indiestep に含まれている(元々は Litestep 0.24.6 に含まれていたんだけどね)日本語処理関係のパッチを行う方法で気づいた物をいくつか列挙。
文中、特に意図して SingleByte(charで表せる文字を指すものとします。単純にはアルファベットのこと)や MultiByte(簡単には僕らが今読んでいるような日本語。)と記述しますが、一般的な言葉なのかは不明です(ぉ
Locate Setting
現在の Indiestep/Litestep は、2001/03頃(情報求むw;)から step.rc の読み込みについて fgetws 関数(ISO/ANSI C, UNIX98準拠の標準ランタイム関数です)を使用しています。
2002/11/27 fgetws 関数の使用時期について、mizu 氏より情報を頂きました。どうもありがとうございました。
おそらく changes.txt のこの辺です。
- Modified [stepsets, winlist, misc / Headius / 2001-02-02]
- Reimplemented StepSettings internally with wide chars (wchar_t)
実際、2001-02-03以降のソースコードでは、 StepSettings::ReadNextLine()でfgetws()が使われています。
この fgetws 関数は、マルチバイト文字列を読み込む際に、自動的に MultiByte → WideChar の変換を行ってくれるのですが、動作に関してはロケールの LC_CTYPE カテゴリに依存します(これは Linuxなどでも同様です)。
このロケールの設定に関しては、既定でまずは “C” ロケール(ANSI定義)として設定されます。
その為、日本語(というかMultiByte文字列)を取り扱うためには、読み込みたい文字列の形式に合わせてロケールの設定を行う必要が有ります。
ロケールの設定には以下のプロトタイプに示される setlocale 関数を使用して設定することが出来ます。
char *setlocale(
int category,
const char *locale
);
自分が何を設定すれば良いのかわからない方は・・・(というか大半はそうだと思いますが)
locale パラメータを NULLと指定することでシステムの規定値を取得、localeパラメータを “” と指定することでシステムの規定値で設定してくれます。
(因みにLinuxなどでは環境変数を参照します。詳しくは man に書いてあるので割愛します)
というわけで、正しく MultiByte の変換を行うために、fgetws 関数を呼び出す前に以下のコードを実行する必要が有ります。
/* presenting default locale to runtime libraries */ setlocale ( LC_CTYPE, "" ); // category は LC_ALL でも可
Litestep の場合、StepSettings クラスのコンストラクタが良いとは思うのですが(理由としては、step.rc の読み込み関連処理を行うクラスだから。それ以外に特に意味は無い)、fgetws 関数を行う前ならば特に問題は無いと思われます。
Creating Font
この問題はかなり古くからあるのですが、 CreateFont ( Indirect ) を使用する際に、CharSet の設定を行わないコードは(SingleByte圏のコードでは特に良く)見られます。一応、以下に CreateFont( Indirect ) のプロトタイプを示します。
HFONT CreateFont( int nHeight, // フォントの高さ int nWidth, // 平均文字幅 int nEscapement, // 文字送り方向の角度 int nOrientation, // ベースラインの角度 int fnWeight, // フォントの太さ DWORD fdwItalic, // 斜体にするかどうか DWORD fdwUnderline, // 下線を付けるかどうか DWORD fdwStrikeOut, // 取り消し線を付けるかどうか DWORD fdwCharSet, // 文字セットの識別子 DWORD fdwOutputPrecision, // 出力精度 DWORD fdwClipPrecision, // クリッピング精度 DWORD fdwQuality, // 出力品質 DWORD fdwPitchAndFamily, // ピッチとファミリ LPCTSTR lpszFace // フォント名 ); HFONT CreateFontIndirect( CONST LOGFONT *lplf // フォントの特性(CreateFontのパラメータを構造体に入れただけ) );
よく見られるコードは以下のコードの様に、特に何も気にせずに 0 を指定したり、構造体を 0 クリアする様な物です。
/* By using 'CreateFont' */ hFont = ::CreateFont(textSize, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, szFontFace); /* By using 'CreateFontIndirect' */ memset(&lf, 0, sizeof(LOGFONT)); lf.lfHeight = nFontHeight; lf.lfWeight = bTitleBold ? FW_BOLD : FW_NORMAL; lf.lfUnderline = bTitleUnderline; lf.lfItalic = bTitleItalic; lstrcpyn(lf.lfFaceName, pszFontFace, LF_FACESIZE); m_hfnTitle = ::CreateFontIndirect(&lf);
これらの様に 0 を指定した場合には・・・ wingdi.h にて定義されている ”ANSI_CHARSET” を指定したことになってしまいます。
しかし、この ANSI_CHARSET は、読んで字の如く、’American National Standards Institute’ の文字セットなので、MultiByte の環境では不具合が出てしまいます。
また、気分的にも、何も指定しないで選ばれるデフォルトよりは、自らの意図をコードに埋め込んだ方がゆっくり眠れる物です。
/* By using 'CreateFont' */
hFont = ::CreateFont(textSize, 0, 0, 0, 0, 0, 0, 0,
SHIFTJIS_CHASET, // in Japan, Default Charset is S-JIS Code.
0, 0, 0, 0, szFontFace);
/* By using 'CreateFontIndirect' */
memset(&lf, 0, sizeof(LOGFONT));
lf.lfCharSet = SHIFTJIS_CHARSET;
lf.lfHeight = nFontHeight;
lf.lfWeight = bTitleBold ? FW_BOLD : FW_NORMAL;
lf.lfUnderline = bTitleUnderline;
lf.lfItalic = bTitleItalic;
lstrcpyn(lf.lfFaceName, pszFontFace, LF_FACESIZE);
m_hfnTitle = ::CreateFontIndirect(&lf);
日本語Windows で使用される文字コードはご存じの通り Shift-JIS です。
ここでは単に文字コードに相当する値を代入しています。
しかし、このコードでは MultiByte 対応ではなく、日本語対応となってしまいそうです。
また、文字コードの違う環境に持っていった場合に動かなくなる可能性も出てきます。
こういった場合にはやはり、自力で頑張るよりもシステム側から論理フォント情報(CreateFontIndirect引数のLOGFONT)を取得するようにする方が Better だと思います。
論理フォントの取得についてはいくつかの方法が有ります。
僕がわかるのは(思い浮かぶのは)以下の二つ。
- SystemParametersInfo API で SPI_GETICONTITLELOGFONT を指定する。
- EnumFontFamiliesEx API などで特定の列挙したフォントを使用する。
EnumFont〜については、僕は詳細を知りません(ぉ
その為、SystemParametersInfo を使用した方法を以下に示します。
/* Getting LOGFONT from system info */
LOGFONT sys_lf;
SystemParametersInfo(SPI_GETICONTITLELOGFONT, 0, &sys_lf, 0);
/* By using 'CreateFont' */
hFont = ::CreateFont( textSize, 0, 0, 0, 0, 0, 0, 0,
sys_lf.lfCharSet, 0, 0, 0, 0, szFontFace);
/* By using 'CreateFontIndirect' */
memset(&lf, 0, sizeof(LOGFONT)); // or copying sys_lf to lf?
lf.lfCharSet = sys_lf.lfCharSet;
lf.lfHeight = nFontHeight;
lf.lfWeight = bTitleBold ? FW_BOLD : FW_NORMAL;
lf.lfUnderline = bTitleUnderline;
lf.lfItalic = bTitleItalic;
lstrcpyn(lf.lfFaceName, pszFontFace, LF_FACESIZE);
m_hfnTitle = ::CreateFontIndirect(&lf);
2002/11/27 EnumFontFamilies 関連に関しても、mizu 氏より情報を頂きました。
詳しくは、以下のアーカイブを参照してください。
tasksの日本語対応作業をやったときに使いました。 JLSUGのメールだと 「[jlsug:448] tasks 0.91 日本語対応」からのスレッド と 「[jlsug:482] tasks 0.92 日本語対応版」からのスレッド にその辺のことが書かれてます。
また、番外編としては・・・ Yoshi さんが公開・・というかご提案されている a2unv.lib (の様に CreateFont の wrap をする方法)を使用するという方のもありかもしれません。
WideChar/MultiByte Patch
日本語の様な MultiByte 文字列を WideChar として取り扱う場合にいくつかの不具合が起きています。
これは単純に変換用のAPIである MultiByteToWideChar / WideCharToMultiByte の使用方法に関する認識違いが(非MultiByte圏の方々はおそらく気づかないでしょう)原因で容易に発生します。
以下に両APIのプロトタイプを示します。
int WideCharToMultiByte( UINT CodePage, // コードページ DWORD dwFlags, // 処理速度とマッピング方法を決定するフラグ LPCWSTR lpWideCharStr, // ワイド文字列のアドレス int cchWideChar, // ワイド文字列の文字数 LPSTR lpMultiByteStr, // 新しい文字列を受け取るバッファのアドレス int cchMultiByte, // 新しい文字列を受け取るバッファのサイズ LPCSTR lpDefaultChar, // マップできない文字の既定値のアドレス LPBOOL lpUsedDefaultChar // 既定の文字を使ったときにセットするフラグのアドレス ); int MultiByteToWideChar( UINT CodePage, // コードページ DWORD dwFlags, // 文字の種類を指定するフラグ LPCSTR lpMultiByteStr, // マップ元文字列のアドレス int cchMultiByte, // マップ元文字列のバイト数 LPWSTR lpWideCharStr, // マップ先ワイド文字列を入れるバッファのアドレス int cchWideChar // バッファのサイズ );
以下、Fig.A にSingleByte の場合の文字列の格納イメージを示します。

この図で示す様に、SingleByte の文字列は、char, wchar どちらに置いても1文字ずつ格納されます。
1文字ずつ格納されているため、この場合の文字列幅も等しくなります。
ところが、日本語の様な MultiByte文字列の場合は、以下の Fig.B に示すように格納されます。
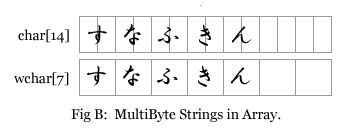
この場合、char[0] は ‘す’ の示す文字コードの上位バイト・char[1]が ‘す’ の下位バイトとなります。
(文字コード ShiftJIS の場合は char[0] → 0x82, char[1] → 0xB7)
しかし、wchar[0] は ‘す’ の示す文字コードそのものを表します(ShiftJISの場合 0x82B7)。
ぱっと見た目でおわかりになるかと思いますが、SingleByte の場合は必要となるバッファサイズは基底となる配列の型に応じて変化(単純には sizeof(char) → 1byte と sizeof(wchar) → 2byte の違い)しますが、MultiByte の場合には変化しません(sizeof(char)*2 → 2byte と sizeof(wchar) → 2byte が等しい)。
その為に以下のコードでは不具合が発生してしまいます。
UINT nChars = min ( UINT( wcslen( src ) +1 ), UINT(256) );
/* this code maybe set src string length +1 to nChars.
* even so, dst needs (src string length * 2) +1 :p
*/
/* Just convert widechar by wrong size */
::WideCharToMultiByte( CP_ACP, 0,
src, // 変換元のポインタ
nChars, // 変換元の幅
dst, // 変換先バッファ
nChars, // 変換先バッファサイズ
NULL, NULL );
この場合、変換元文字列幅+1 が(たとえそれ以上に変換先が確保されていたとしても)バッファのサイズ( sizeof(char) * nChars で確保されているもの )とされてしまうことになります。
その場合、足りない部分に関しては切りつめられます(”未検証”)。
とりあえず、受け側には充分なバッファを用意したとして、上記のコードは以下の様に改善出来ます。
/* Leave caluculating size to API */ ::WideCharToMultiByte ( CP_ACP, 0, src, -1, dst, sizeof(dst), NULL, NULL );
変換元の幅に関しては、cchWideChar に -1 を指定することでNULL終端文字列ならば自動的に長さが計算されます。 (wcslen(src)で自力で計算するのも良いかと思いますがw;)
また、バッファサイズは cchMultiByte に 0 を指定することで必要数が取得できる為、以下のコードの方が良いのかもしれませんが・・・面倒です(貴様
/* Getting buffer size, by specifying 0 to cchMultiByte */
UINT dst_len = ::WideCharToMultiByte( CP_ACP, 0, src, -1, NULL, 0, NULL, NULL );
// cchMultiByte を 0指定でバッファサイズが得られる
/* Allocate buffers in obtained size */
dst = new TCHAR[dst_len];
/* Here, convert widechar */
::WideCharToMultiByte ( CP_ACP, 0, src, -1, dst, dst_len, NULL, NULL );
これらの処理は、逆に MultiByteToWideChar を行う場合にも同様になります。
(ただし、MultiByteからWideChar への変換は、逆の場合と違いあふれ(というか?)の問題が無いため、なかなか表面化しにくいバグになります)
情報元
mzks.org/Litestep
mzks build を参考にしました。特に、locale 関連は以前MLで大半を水越氏に教えていただいた物です。
litestep localization project jpn ML
上記関連の議題が有りました
(現在MLは Litestep メーリングリスト に統合(?)されてます)
- スポンサードリンク -